Constrained Policy Optimization via Sampling-Based Weight-Space Projection
Dec 1, 2025· ,·
0 min read
,·
0 min read
Shengfan Cao
F. Borrelli
Abstract
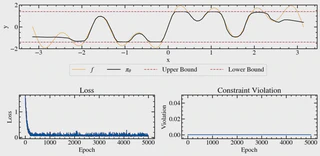
Safety-critical learning requires policies that improve performance without leaving the safe operating regime. We study constrained policy learning where model parameters must satisfy unknown, rollout-based safety constraints. We propose SCPO, a sampling-based weight-space projection method that enforces safety directly in parameter space without requiring gradient access to the constraint functions. Our approach constructs a local safe region by combining trajectory rollouts with smoothness bounds that relate parameter changes to shifts in safety metrics. Each gradient update is then projected via a convex SOCP, producing a safe first-order step. We establish a safe-by-induction guarantee: starting from any safe initialization, all intermediate policies remain safe given feasible projections. In constrained control settings with a stabilizing backup policy, our approach further ensures closed-loop stability and enables safe adaptation beyond the conservative backup. On regression with harmful supervision and a constrained double-integrator task with malicious expert, our approach consistently rejects unsafe updates, maintains feasibility throughout training, and achieves meaningful primal objective improvement.
Type
Publication
IFAC World Congress 2026 (Under Review)

Authors
Shengfan Cao
(he/him)
PhD Researcher in Autonomous Driving & Robotics
PhD researcher with 3+ years of hands-on experience in autonomous driving and robotic systems, spanning safe learning, control, and end-to-end autonomy deployment. I am transitioning into industry to work where large-scale data and real-world constraints continuously shape and validate learning-based autonomous systems.
Authors