Sampling-Based Constrained Policy Optimization
Sep 1, 2025
·
1 min read
Principal Researcher (Sep 2025 — Dec 2025)
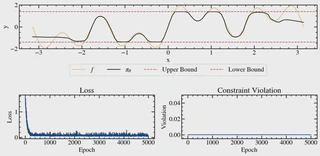
- Proposed a sampling-based weight-space projection framework for enforcing safety constraints during policy updates, enabling scalable safe learning for large neural policies.
- Formulated policy optimization as a convex projection in parameter space, with theoretical guarantees that projected updates preserve objective improvement.
- Derived a sufficient stability condition linking weight updates to closed-loop constraint satisfaction, and embedded it directly into the optimization pipeline.
- Empirically demonstrated complete rejection of harmful supervision and safe performance gains in regression and imitation learning under adversarial experts.
Tech: PyTorch, Convex Optimization, Reinforcement Learning, Safe Learning.

Authors
Shengfan Cao
(he/him)
PhD Researcher in Autonomous Driving & Robotics
PhD researcher with 3+ years of hands-on experience in autonomous driving and robotic systems, spanning safe learning, control, and end-to-end autonomy deployment. I am transitioning into industry to work where large-scale data and real-world constraints continuously shape and validate learning-based autonomous systems.